
 by
by So I was pondering the other day – imagine that I had a cloud and an urgent need to deploy a virtual machine into a newly created network with a firewall rule protecting it. How would I do that? Believe it or not, I counted 5 ways so far, and there could be even more (e.g. dispatch a saboteur with a soldering iron into a data centre). All approaches have different pros and cons, so I just had to write them down. Here they are:
1. Deploy using a cloud console
This is the most obvious and probably the most widely used approach nowadays. Every self-respecting cloud provider has a web portal, usually called a console (console.cloud.google.com, console.aws.amazon.com etc.). It’s a set of a web forms, usually of a questionable design (I’m looking at you, Microsoft and Amazon), where through a set of clicks and curse words we can create almost anything.
That’s how creating the stuff we talked about would look like in Google Cloud Console:
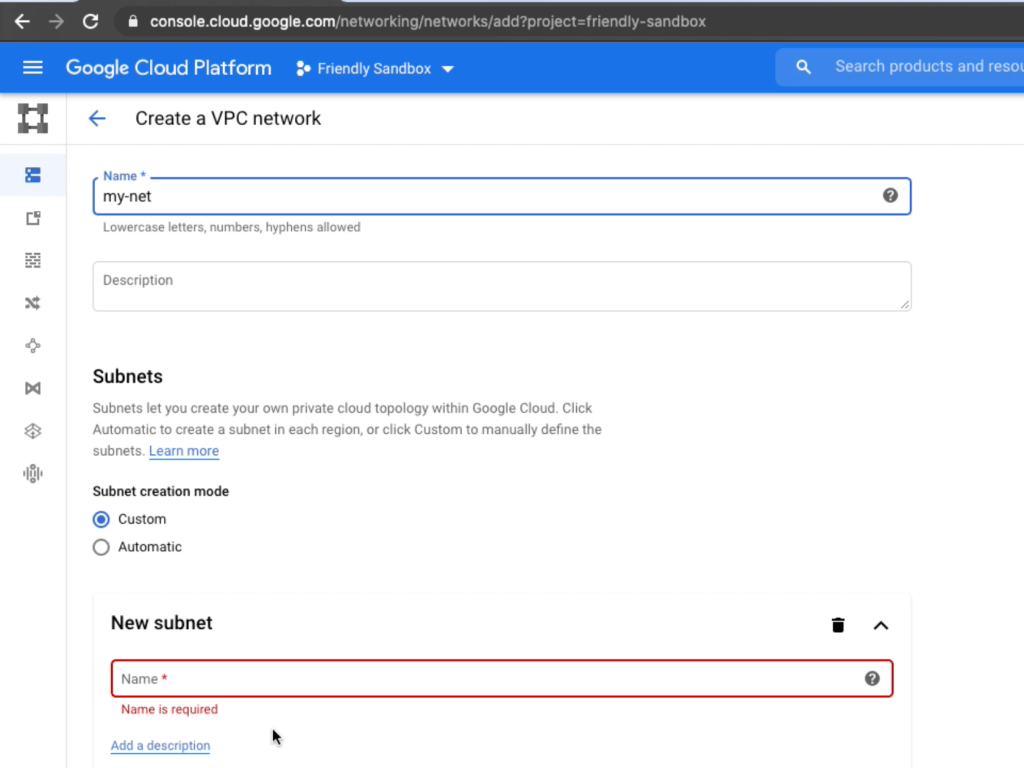


It’s a good approach, but like anything else in this world, it has pros and cons.
Pros:
- It’s probably the simplest way to create stuff. Cloud providers usually leave some wizards and clues about how and what to create, and that helps. Plus, some complex resources like Google Load Balancers are way easier to configure via the console, than through anything else.
- That’s the perfect approach for experiments. If I’m not sure if I can peer from network A to network C through network B – clicking through the console and trying the assumption sometimes is faster than just googling.
Cons:
- This. Is. Not. Scalable. I can create one virtual machine through clicks and buttons, but what about ten? A hundred? I’ll probably die of boredom.
- Repeatability. Even if I decide to create 10 VMs via console, due to the fat fingers and occasional alcohol abuse, some of these machines will be configured differently than the others. And there’s always that guy that simply cannot follow the instructions exactly as he was told, so 10 VMs will end up being not just different, but all of them will be wrongly different. Humans…
But overall, the cloud wouldn’t have been the same without the console. We’ll always need it.
2. Deploy via SDK CLI
Another set of tools that every self-respecting provider has – a command line SDK. Instead of clicking and browsing we’ll be typing and scripting, but the result will be the same – a VM in a network with a firewall rule in it. It’s still quite simple approach, as even Google managed to come up with CLI tools that are actually intuitive.
Here’s how creating the aforementioned set of cloud resources would look by using Google SDK CLI:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
PROJECT="some-friendly-sandbox" ZONE="us-central1-a" VPC_NAME="my-net" gcloud compute networks create $VPC_NAME \ --project=$PROJECT \ --subnet-mode=auto gcloud compute firewall-rules create my-net-allow-ssh \ --project=$PROJECT \ --network=projects/$PROJECT/global/networks/$VPC_NAME \ --direction=INGRESS \ --priority=65534 \ --source-ranges=0.0.0.0/0 \ --action=ALLOW \ --rules=tcp:22 gcloud beta compute instances create my-instance \ --project=$PROJECT \ --zone=$ZONE \ --machine-type=f1-micro \ --network=projects/$PROJECT/global/networks/$VPC_NAME \ --no-service-account \ --no-scopes \ --image-project=ubuntu-os-cloud \ --image-family=ubuntu-1804-lts \ --boot-disk-size=10GB \ --boot-disk-type=pd-standard \ --boot-disk-device-name=my-instance-disk |
The script looks a bit larger than you’ve probably expected, but that’s probably because I tried to look smart and professional, and that doesn’t always work well. But even if you never dealt with Google Cloud Platform, just reading the command names would be enough to understand what’s going on there. Even the console at times cannot be that transparent. Pros and cons are also there:
Pros:
- It’s still relatively simple. Commands are quite intuitive, you just need to google them first.
- The approach is somewhat scalable. You wouldn’t use it to script a whole bank infrastructure, but for a set of similar static resources – why not?
- It’s repeatable. Making 10 VMs instead of 1 means copy-pasting the same command 9 times.
- These commands are text, and text can be stored in git, and that’s precious. Even if CLI is all you’re going to use, being able to store the commands and see the annotated history of change is invaluable. Infrastructure must be in git – there’s no other way.
Cons:
- Scalability is still limited. Creating 10 identical VMs is indeed simpler with CLI, but supporting hundreds of networks with subnets, VM, accounts and their interdependencies in shell scripts and CLI is virtually impossible.
- How do I put it.. There’s no direct connection between the set of CLI commands that you have, and an actual state of the cloud. Say, I have a shell file that creates a VM. What if the VM is already there? The script will fail. What if the VM is just slightly different from my commands set (e.g. new resource tags were added), should I write
if‘s andelse‘es to handle that scenario? - Having CLI commands for infra creation still means we’ll need to create another set to delete them. Resources do come and go, you know.
- Sometimes there won’t be access to CLI. What if you have a Cloud/Lambda function that reacts on events and instantiates requested resources (e.g. VMs to execute a unit test suite on). There’s no file system in serverless.
But even taking the cons into account, if I have more than one long-lived cloud resource and a choice between the console and CLI, I’ll choose CLI every time. Because I want to keep a history of how I created that stuff. However, some of the cons can be addressed by the next deployment approach.
3. Using a cloud API directly
CLI tools are using Cloud API, and nothing says we can’t do the same. This way, we can choose any general purpose programming language and cloud the hell out of things. If we don’t have access to the file system – API is the way. If we don’t want to install Azure SDK of version X, because believe me when I say that sometimes you’ll have to uninstall it and download an older version, because the latest one is broken, – API is the way. API never lies and is rarely broken. Most of the time, there will be API clients for all popular languages, and sometimes they are even simple to use.
Here’s how we’d create a VPC, a VM and a firewall rule in Python:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 |
import os import time import googleapiclient.discovery zone = 'us-central1-a' def get_instance_config(zone, network_link): return { 'name': 'my-instance', 'machineType': f'zones/{zone}/machineTypes/f1-micro', 'network': '', 'disks': [ { 'boot': True, 'autoDelete': True, 'initializeParams': { 'diskName': 'my-instance-disk', 'diskSizeGb': 10, 'diskType': f'zones/{zone}/diskTypes/pd-standard', 'sourceImage': 'projects/ubuntu-os-cloud/global/images/family/ubuntu-1804-lts', } } ], # Specify a network interface with NAT to access the public # internet. 'networkInterfaces': [{ 'network': network_link, 'accessConfigs': [{ 'type': 'ONE_TO_ONE_NAT', 'name': 'External NAT', }] }], } def get_network_config(network_name): return { 'name': network_name, 'autoCreateSubnetworks': True } def get_firewall_config(network_link): return { 'name': 'my-net-allow-ssh', 'network': network_link, 'priority': 65534, 'sourceRanges': ['0.0.0.0/0'], 'allowed': [{ 'IPProtocol': 'tcp', 'ports': ['22'] }], 'direction': 'INGRESS' } def find_network(client, project, network_name): result = client.networks().list(project = project).execute() networks = result.get('items', []) return next(filter(lambda net: net['name'] == network_name, networks)) def wait_for_operation(compute, project, zone, operation): while True: if zone: result = compute.zoneOperations().get( project = project, zone = zone, operation = operation['id'] ).execute() else: result = compute.globalOperations().get( project = project, operation = operation['id'] ).execute() if result['status'] == 'DONE': if 'error' in result: raise Exception(result['error']) return result time.sleep(1) def create_instance(client, project, zone, network_link): operation = client.instances().insert( project=project, zone=zone, body=get_instance_config(zone, network_link) ).execute() wait_for_operation(client, project, zone, operation) def create_network(client, project, network_name): operation = client.networks().insert( project=project, body=get_network_config(network_name) ).execute() print('Waiting for network to be provisioned') wait_for_operation(client, project, None, operation) def create_firewall_rule(client, project, network_link): operation = client.firewalls().insert( project=project, body=get_firewall_config(network_link) ).execute() print('Waiting for firewall to be provisioned') wait_for_operation(client, project, None, operation) def deploy_stuff(project, zone): print('Creating a client') client = googleapiclient.discovery.build('compute', 'v1') network_name = 'my-net2' print('Creating a network') create_network(client, project, network_name) print('Finding newly created network') network = find_network(client, project, network_name) network_link = network['selfLink'] print('Creating a firewall rule') create_firewall_rule(client, project, network_link) print('Creating an instance') create_instance(client, project, zone, network_link) if __name__ == '__main__': project = 'some-sandbox-project' zone = 'us-central1-a' deploy_stuff(project, zone) |
That’s even more code than with SDK CLI, but half of it is print statements, so it’s bearable. This code can create one VM or with little modification – a dozen of them. if‘s, then‘s, else's are there, so I can create/update/delete stuff all day long.
However, as always, pros of this approach are nicely accompanied with cons.
Pros:
- File system access is no longer needed
- All power of general purpose programming language can handle any exotic deployment scenario
- Git, scalability and repeatability – they are still there
Cons:
- The power of a language is also its problem. For some reason, I never saw an imperative code that creates an infrastructure, which also could be readable by humans. Something between the nature of cloud resources and general purpose imperative languages just doesn’t click. The same is true regarding CI/CD pipelines configurations, by the way. The worst CI/CD stuff I ever saw was written in imperative languages.
- Creating resources via API calls is hard. It just is. Look at the amount of the code above.
- APIs aren’t created equal. Google API is more or less consistent and predictable, but Microsoft Azure API was… unorthodox.
- Though API is the truth, it does change. Sometimes without backward compatibility.
But creating cloud resources with API has valid use cases, so why not. Especially if we can handle almost all other use cases by next approaches.
4. Cloud provider native deployment tools
Most of the time Cloud providers come with native deployment language and tools, and most of the time they can address almost all the cons of the approaches above. I’m talking about Cloud Deployment Manager for Google, ARM Templates for Azure and CloudFormation for AWS. These guys are declarative languages, which prevents the imperative hell, supports input parameters, passing outputs of one set of resources as inputs to the others, which helps to split resources deployment into logical stages via declarative dependencies tree. What’s even cooler, native deployment tools treat an act of deployment as a special kind of resource, which allows them to keep track of changes in the deployment and gracefully apply them to existing resources. It goes without mentioning that often (not always) deleting the deployment deletes underlying resources as well.
Here’s how aforementioned resources’ deployment would look in Google’s Deployment Manager’s YAML format.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 |
resources: - name: my-net type: compute.v1.network properties: autoCreateSubnetworks: true - name: allow-inbound-ssh type: compute.v1.firewall properties: network: $(ref.my-net.selfLink) priority: 65534 sourceRanges: - 0.0.0.0/0 allowed: - IPProtocol: tcp ports: - "22" direction: INGRESS - name: my-vm type: compute.v1.instance properties: zone: us-central1-a machineType: zones/us-central1-a/machineTypes/f1-micro network: $(ref.my-net.selfLink) disks: - deviceName: boot boot: true autodelete: true initializeParams: diskName: my-instance-disk diskSizeGb: 10 diskType: zones/us-central1-a/diskTypes/pd-standard sourceImage: projects/ubuntu-os-cloud/global/images/family/ubuntu-1804-lts networkInterfaces: - network: $(ref.my-net.selfLink) accessConfigs: - name: external-nat type: ONE_TO_ONE_NAT |
Not all deployment tools are created equal, though. From what I tried, I like Google’s DM the most, as it’s compact, simple, almost up to date with existing APIs and supports a few features that make it a king among the others: type providers and Python / Jinja templates. Type providers allow you to connect REST API to deployment manager, which is an effective way to fill in the gap between the actual types of resources that the cloud has with ones that are currently supported by DM. Templates on the other hand allow to overcome the limitations of a declarative language and embrace the doom of an imperative one – if‘s, else’s – you know the drill.
On the other hand, there’s Azure’s ARM Templates. I think they rolled out something new too – Blueprints or something – but the main tool was ARM and I hated it. When the whole world moved from XML as configuration language to JSON, Microsoft was still stuck to a decomposing corpse of XML (I liked XSLT, though). As soon as the world moved to YAML or comparable DSLs, MS finally decided to move to JSON. ARM templates are written in JSON, and that’s killing me. Amazon’s CloudFormation is JSON too, but somehow it sits at the edge of being bearable.
Never in my life was I able to create an ARM template that would just work. The simplest thing, like creating a virtual machine scale set (VM instance + autoscaler in Google terms), would never work, no matter what the official documentation would say. Even copy-pastable examples would have some syntax errors, obsolete key names, or similar problems. Even if I found the solution of a problem, unless I had the code nearby, the nest problem of the same kind would require the googling again. It was that not obvious. For comparison, after 2 years of not doing Deployment Manager at all, I was able to create a sample for this post in minutes with one easily resolvable typo. Not all deployment tools are created equal, that’s all I’m saying.
Speaking about more structured lists of pros and cons:
Pros:
- Deploying one resource or dozens of them is no longer a problem.
- Deployment files are
git’table and easily repeatable. - Deployment files can be submitted by CLI, API or even a console.
- Usually, deployed resources can be created, updated and deleted using the same deployment file.
Cons:
- Some native deployment tools just suck, and no praying and animal sacrificing can fix that. Some essential feature can be missing, making the whole tool useless.
- Even a good cloud native deployment tools can lack of support of up-to-date cloud resources. Even though the tools are created by the cloud provider itself. In order to deploy Google’s Cloud Functions via DM, I had to import their CF API as a type provider, as from DM’s point of view Cloud Functions were still in beta.
- Only ‘home’ cloud resources are usually supported. If you have a hybrid infrastructure to deploy, e.g. AWS + Google – good luck with that.
- Only cloud resources are supported. If you want to manage something like a
gitrepository or git repo manager as a resource using cloud native deployment tool – good luck with that as well.
But if you’re lucky with your cloud provider and the task itself, cloud’s deployment tool can be awesome. I still remember my Deployment Manager experience with warmth. Having 4 approaches at my disposal, DM was the best one. However, if you’re dealing with complex, hybrid multi cloud deployments, keep reading.
5. Terraform
In my previous life as a cloud consultant, we started off by recommending using a cloud provider’s native deployment tool over Terraform. After all, Google knows its own cloud better, right? Well, in a year we realized that’s no, not really. Though a cloud provider might know its cloud better, it doesn’t really know how people are supposed to use it. And for some reason, Terraform does. In addition to supporting whatever every provider supported, it also had rudimentary flow control structures (if’s, loop’s), while remaining a declarative language.
It also provided a full control over where the state (the knowledge about what resources have been deployed and what input/output parameters they should have) – it could be stored in AWS S3, Google Cloud Storage, locally – you name it. Data pieces from the state could be referenced from other deployments, which essentially is a fast lane for creating multi-stage / multi-repository deployments. For instance, one deployment pipeline could create permanent infrastructure piece – projects, accounts, organization policies, etc. It’s outputs (project IDs, etc) would go to some centralized storage as a state, and then transient infrastructure components – ones corresponding to particular application or team (networks, VMs, storage buckets) – would use the data pieces from the first deployment as input parameters for itself. Then, modules for code reusability, SDKs for writing custom resource providers – all of that would help us to build the largest infrastructure projects we could come up with.
Some projects that I saw could never be written in Deployment Manager. Not without shooting one’s legs off first. That’s why we switched to Terraform.
Here’s how a VM, a network and a firewall rule would look in TF:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 |
provider "google" { project = "friendly-sandbox" } resource "google_compute_network" "this" { name = "my-net" auto_create_subnetworks = true } resource "google_compute_firewall" "this" { name = "my-net-allow-ssh" network = google_compute_network.this.id allow { protocol = "tcp" ports = [22] } direction = "INGRESS" priority = 65534 source_ranges = ["0.0.0.0/0"] } resource "google_compute_instance" "this" { name = "my-instance" machine_type = "f1-micro" zone = "us-central1-a" boot_disk { initialize_params { size = "10" type = "pd-standard" image = "ubuntu-os-cloud/ubuntu-1804-lts" } } network_interface { network = google_compute_network.this.id access_config { } } } |
It’s not huge, maybe a bit bigger than Google’s DM, but way smaller than raw API calls, and much more maintainable than the Console or CLI. Pros and cons though do exist as well.
Pros:
- Importing existing resources, creating, updating and removing new ones – it’s all supported.
git, scalability and repeatability – the same.- Storing deployment state in an external location allows multiple deployment pipelines to coexist within one environment.
- All major cloud providers and custom resource types (e.g. git repositories) are supported.
- What is not supported can be implemented via Terraform plugin SDK (I had to implement Azure Subscriptions support twice!).
There’re probably a few cons:
- I don’t think Terraform can be used without the file system being around. Probably they have some Enterprise feature to handle that, but I remember local
terraformexecutable being a requirement. - There are not many people in the world who know how to write big infrastructure projects in Terraform. It’s not really a TF problem, the same applies to every approach, but it’s there. Everyone seems to be coming up with a new wheel as they go.
- Some Terraform releases aren’t exactly backward compatible. I remember we switched to either 0.12 or 0.13, and out of the sudden I had to re-google where the plugin directory should be now.
But other than that, Terraform is my default choice for cloud deployments.
Summary
So, in this surprisingly long blog post, we’ve walked through the whole 5 ways of deploying the stuff into the cloud. If I could summarize them in one paragraph (and I can do that), that would be something like this:
Use cloud web console for discovery and experiments, SDK CLI for bigger experiments or long-lived standalone resources, cloud API for serverless environments and scenarios that require creating of temporary resources just for given runtime task (e.g. allocating a set of VMs for running a test suite), cloud native deployment tools for simple cloud infrastructure deployments and Terraform for everything else. Now you know it all.



Great content mr Klimiankou!
That’s what I do 🙂